
GIANT AI Guide for Educators: Responsible AI

“Responsible AI” is an important area of research that studies ways to train LLMs based on human values and preferences. A popular framework called HHH, short for Helpful, Honest, and Harmless, provides a set of principles that guides developers in the responsible use of AI. Educators may use this framework to discuss responsible uses of AI with their students, and engage them in learning about techniques developers might use to develop AI responsibly.
Helpful
To be helpful, a model needs to complete tasks accurately. However, sometimes models provide wrong information. Due to the nature of how Large Language Models are trained, developers don’t really know what the model is actually learning, and sometimes models try to fill gaps or “make up” answers where it has missing data - resulting in false statements or “hallucination” as AI engineers call it.
To protect users from potential misinformation when using AI models, it is extremely important to educate users on how generative AI works and the ways they can verify or check the accuracy of the LLMs’ outputs. Here are few recommendations as you introduce students to AI:
Metaphors we use matter - Do not refer to AI as the “genius” that knows all answers or as something “magical.” Instead, help your students to think of AI as a tool that can make mistakes and should be used cautiously.
Study intended versus unintended use-cases of the particular model or application you are using. For example, some models may be trained or fine-tuned to do specialized tasks such as legal work, accounting, or scientific research, whereas others are not trained to do these tasks. Knowing the limitations and capabilities of models we are using can inform us about potential misinformation, especially in areas the model is not trained to perform tasks.
Teaching students ways to double check accuracy of the AI outputs against verified and trusted sources. Asking AI to provide citations for factual points it generates, and then checking those references for accuracy and validation is highly encouraged.
Harmless
To be harmless, LLM applications should be designed to minimize toxic language that can be (1) harmful or discriminatory towards certain groups of people, (2) offensive, or (3) eliciting criminal behavior. Responsible AI developers employ certain techniques to avoid harmful completions by their models as much as possible. One of these techniques is called Reinforcement Learning from Human Feedback (RLFM). This technique involves optimizing LLM outputs based on feedback obtained from humans. To understand how this technique works, you may do the following activity with your students.
Try this activity with your students. Ask your students if any of them have ever trained a pet, for example a dog. Discuss how they might have rewarded their dog with a treat when their dog behaved well based on their instruction, and ask them if rewarding their dog for the “good” actions resulted in their dog doing better over time. Rewarding for “good behavior” based on human feedback is how AI developers fine-tune their models to behave responsibly based on human values and preferences. Similar to dogs, this learning process for AI models is iterative and involves trial and error. So how do AI developers do that? They ask human “labelers” to give points to possible AI completions/responses based on a set of rules. They will then use this “rewarding database” to readjust parameters that AI models use to calculate probabilities they assign to words when they generate responses.
Remember how you tried to “guess” what’s the best word to use to complete the sentence “A dog is…?” Now imagine the person you were trying to complete the sentence for was a scientist who gave you a point when you completed the sentence with scientific facts about dogs and didn’t reward you if you used words like “cute or annoying.” If you play this game with the scientists for a few rounds, the chances are that you learn through reinforcement from feedback that a “good” or “acceptable” way of responding is to respond scientifically. That is you “readjusting” the parameters you use to guess the probability of which words in your “space” may be a suitable response based on the “rewards” you receive. How would you behave if you were going to play this game with a pet shop owner? Or someone who practices Islam as their religion? This process of “readjusting” parameters to calculate probabilities is called “fine-tuning” in the AI development world.
Now, let’s try to create a reward database to truly understand what goes into fine-tuning models to behave responsibly based on human values and preferences, and understand the importance of including diverse voices in the process.
Ask your students to assign points to these prompt-response sets based on an Alignment Criterion you set as a community. For example, you can set the criterion to be “helpfulness.” Next, together create instructions for human labelers (aka your students) and then ask them to rate (1 being the worst answer and 3 being the best answer) each of these responses presented in this GIANT dataset.
Below is a sample instruction for human labelers (aka your students):
Rate each of these responses from 1 to 3, 1 being the worst answer and 3 being the best answer to the prompt.
Rate based on these criteria: (1) alignment with your interests, (2) being harmless, and (3) being feasible.
If two responses provide the same alignment with your interests, harmlessness, and feasibility, and there is no clear winner, you may rate them the same, but try to rate responses differently as much as possible.
If a response is nonsensical, irrelevant, highly confusing, or does not answer the question at all, label it with “F” (for fail) rather than rating it.
Once they all rate responses, discuss the importance of having diverse voices when setting the alignment criterion, defining rules for human labelers, and who these human labelers might be when they try to “fine-tune” AI models to behave responsibly.
One final note to make is that, as you can imagine, obtaining human feedback can be time consuming and expensive. To overcome this barrier, AI developers use an additional AI model, known as a reward model, to rate or classify outputs of LLMs and evaluate the degree of alignment with human preferences. However, the exercise you went through highlights the importance of diversity in the community of AI developers and not just the datasets.
This discussion illustrates three important steps AI developers can take to reduce toxicity in their models, designing AI applications that are less harmful and more aligned to human preferences and values. These steps involve:
Using training data that is not biased – This is extremely difficult because to train LLMs big datasets are needed, and these datasets are usually generated using publicly available information on the internet. Unfortunately, there is so much toxicity and bias on the internet, making it very difficult to put together an “unbiased” dataset. Nevertheless, it is important to be mindful of toxicity in training data.
Include guardrails on top of trained models to fine-tune them – These guardrails support removing “unwanted” content that may be toxic and unsafe.
Work with a diverse group of human labelers – It is extremely important to include voices of diverse groups of humans to build AI in a responsible way. This does not mean all people need to be programmers, but as you saw in the simple exercise above, even if you do not have any computer science background, you do have opinions, and the way you “rate” information can have a huge influence on the way these models behave.
This discussion also highlights responsibilities that are on “users” of these AI tools:
Critique AI outputs – As users, we need to be mindful of the flaws and capabilities of the tools we use — and use them responsibly. Learning how to be a responsible digital citizen needs to start early and needs constant practicing. Learning what concepts such as “hate speech,” “fake news,” “body shaming,” “racism,” “sexism,” or “indecency” mean and discussing these issues, within the context of AI or within our day-to-day life experiences, can help us to become better citizens in the physical and digital world.
Know the language and demand more responsible AI – Knowing how AI works helps us to know how to ask questions and how to choose AI applications that may do less harm. For example, educators and students can ask about guardrails in the application, intended use-cases, sources of training data, and demand better practices from developers.
Engineer your prompt – By altering our prompts and using specific prompt engineering techniques, such as In Context Learning (ICL), we can influence how AI models respond. This is a power in the hands of users of these applications — a power that only enhances with education.
Honest
To have an “honest” AI system, we need to consider (1) how LLM models are developed, (2) how users use these models, and (3) what policies are in place to govern these systems. Here we discuss each of these three pillars separately with the goal to inform educators and students on best practices for an “honest” use of AI.
Honest LLM Models: LLM models have been trained on massive datasets available on the internet. There are many concerns about accuracy, validity, and copyright issues in building the foundation of these models. As users, we can demand a more “honest” practice from developers by asking questions about sources of their training data and, when possible, use systems that are “honest” in how they have been trained and how they attribute credits. For example, here is what Adobe Firefly explains about sources of their training data. Does this feel “honest” to you? Try to compare this application with another AI application and ask yourself which one is more “honest,” and which one you may want to use as a user.
Trained on Adobe Stock images, openly licensed content, and public domain content, Firefly is designed to be safe for commercial use. To ensure that creators can benefit from generative AI, we've developed a compensation model for Adobe Stock contributors whose content is used in the dataset to retrain Firefly models.
“Honesty” is not only about the nature and source of the training data, but also about the way LLMs handle users' data and privacy. For example, before April 2023, ChatGPT stored all users’ information and data provided as part of their account, in the context of their prompts, chat history, as well as IP address of their device, and used this data to further train its model. This is why it is extremely important to not disclose “private” and sensitive information to these models. In April 2023, ChatGPT released a setting option for users to “turn off” their chat history so that their data won’t be used to further train the models. To keep your data secure, you need to know (a) that this option exists, and (b) how to actually change the setting. Discuss with your students what is an “honest” way of designing these models: Is it more honest to “turn off” chat history by default and only use users’ data when they turn on the setting, or is it more honest to use users data by default unless they “turn off” their chat history?
Below, you can see how you can “turn off” your chat history in ChatGPT:

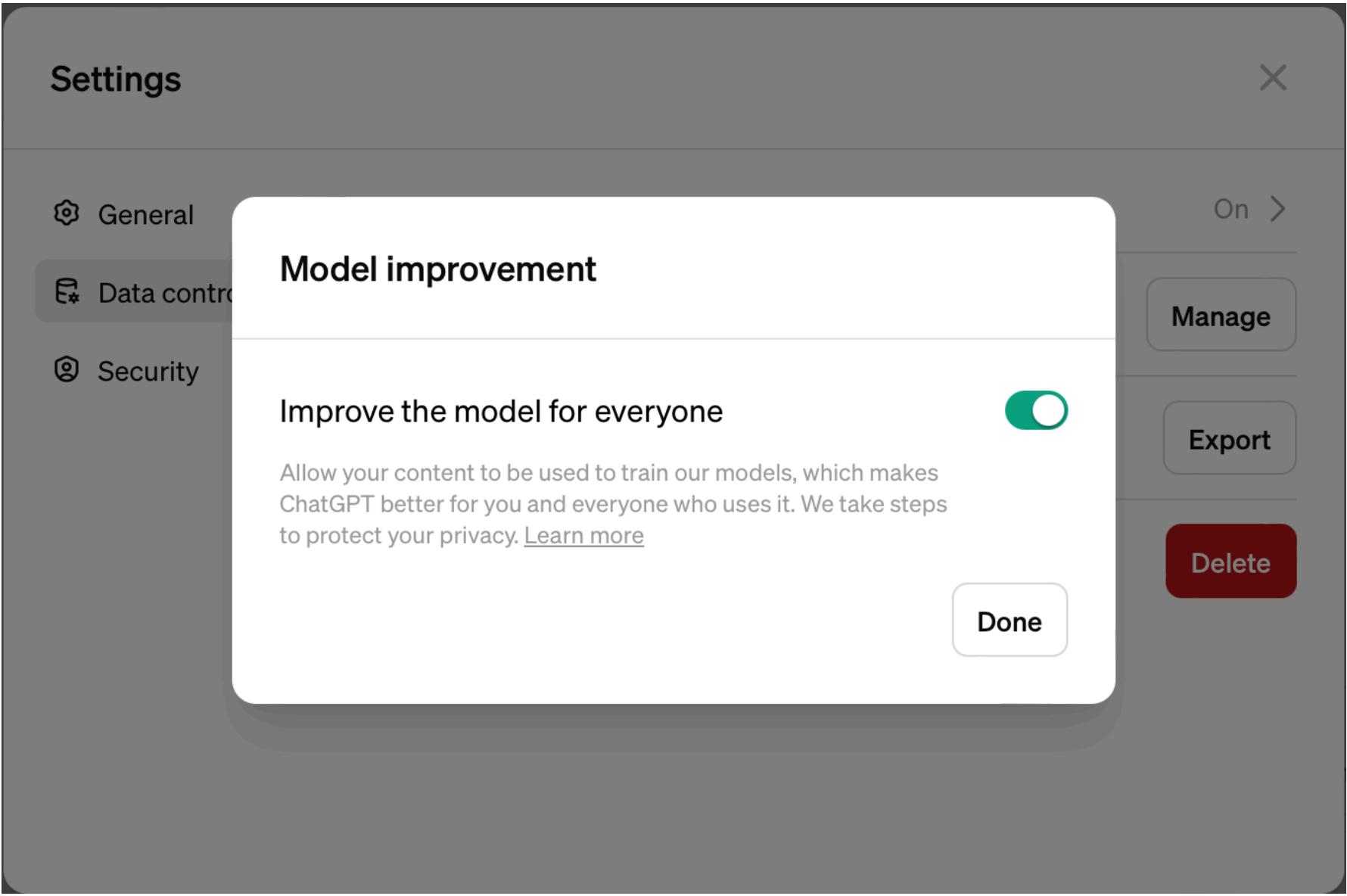
As you can see, by default the application’s setting is set to use users’ data in their training, but gives the option for the user to opt out of sharing data. Does this feel “honest” to you?
In addition to being transparent and honest on how they have trained the models and giving options to users to opt in and out of sharing their data, AI developers and researchers can employ certain techniques to handle private user data. One such technique is called Retrieval Augmented Generation (RAG) which is a framework for building LLM powered systems that makes use of external data sources, but does not integrate this data as part of the training process. In other words, RAG framework allows LLM applications to work with private and sensitive data without using this data to alter its parameters. This framework could be a great framework for AI powered applications in the education settings where students data needs to be kept private. It is important to note that the field of Responsible AI is new and constantly evolving, and as users, we need to try to understand what’s possible so we can choose these tools in an educated way.
This discussion highlights responsibilities that are on “users” of these AI tools:
Ask where does the training data come from, what are the sources, and if there are Copyright concerns
Understand how your data is being treated and what your options are as a user to protect your data
Demand more responsible and honest applications by asking the right questions when choosing such applications
Honest users of AI applications: Being honest is not only on the developers of these systems, but also a big responsibility of the users of these applications. As users, we need to:
Be honest on what, when, and how we use AI tools in our work. This means, we (students and educators) need to cite any AI tools we use (including information about models and prompts) and the way we used the tool in our work.
Understand norms of what is an acceptable and what is not an acceptable use of these applications in the context of school, work, home, or personal life.
Always be cautious of the data we share on AI systems and avoid sharing private or sensitive data unless we are confident that our data will remain secure.
Understand privacy setting options available to users and change these settings wisely.
When possible, choose “honest” applications over “dishonest” ones, which in turn makes developers accountable to be more honest in their practices.